Pacers are human beings like every other runner. They can make mistakes, get injured, get tired, and so many other unforeseen situations. When we decide to follow a pacer we have to accept that anything can happen in such a long course, which might result in glory or frustration. It is about accepting a variable we can’t control. I had a personal experience with a pacer who was going faster than the average pace for the goal time. Most of my fuel was burned in the first half of the course, leaving me exhausted in the second half.
Let’s use LibRunner to investigate the case. If you are not familiar with LibRunner yet, read [an introduction we published previously] to learn how to run the following code. As published in Strava, the 4:10h pacer of the Calgary Marathon 2023 was running too fast for more than 30 km. But first, what is the average pace we would expect from him to finish the marathon in 4:10 hours?
use librunner::running::{Race, MetricRace, ImperialRace, Running, MetricRunning, ImperialRunning};
use librunner::utils::converter;
use librunner::utils::formatter;
fn main() {
const MARATHON_DISTANCE: u64 = 42195; // meters
let duration = converter::to_duration(4, 10, 0);
let marathon: MetricRace = Race::new(MARATHON_DISTANCE);
let running: MetricRunning = Running::new(duration);
println!("The pace to run a marathon in {}h is {}/km",
formatter::format_duration(running.duration()),
formatter::format_duration(running.average_pace(&marathon)));
}
It prints: “The pace to run a marathon in 04:10:00h is 05:55/km”. Looking at his splits, he was mostly below this pace and only slowed down in the last 8 km to the finish line. So, what was his average pace before he slowed down? Adding to the previous code:
let mut splits: Vec<Duration> = Vec::new();
splits.push(converter::to_duration(0, 5, 53)); // 1km
splits.push(converter::to_duration(0, 5, 38)); // 2km
splits.push(converter::to_duration(0, 5, 44)); // 3km
splits.push(converter::to_duration(0, 5, 37)); // 4km
splits.push(converter::to_duration(0, 5, 29)); // 5km
splits.push(converter::to_duration(0, 5, 43)); // 6km
splits.push(converter::to_duration(0, 5, 33)); // 7km
splits.push(converter::to_duration(0, 5, 46)); // 8km
splits.push(converter::to_duration(0, 5, 30)); // 9km
splits.push(converter::to_duration(0, 5, 33)); // 10km
splits.push(converter::to_duration(0, 5, 27)); // 11km
splits.push(converter::to_duration(0, 5, 33)); // 12km
splits.push(converter::to_duration(0, 5, 37)); // 13km
splits.push(converter::to_duration(0, 5, 25)); // 14km
splits.push(converter::to_duration(0, 5, 42)); // 15km
splits.push(converter::to_duration(0, 5, 54)); // 16km
splits.push(converter::to_duration(0, 5, 42)); // 17km
splits.push(converter::to_duration(0, 5, 41)); // 18km
splits.push(converter::to_duration(0, 5, 50)); // 19km
splits.push(converter::to_duration(0, 5, 51)); // 20km
splits.push(converter::to_duration(0, 5, 43)); // 21km
splits.push(converter::to_duration(0, 5, 39)); // 22km
splits.push(converter::to_duration(0, 5, 43)); // 23km
splits.push(converter::to_duration(0, 5, 37)); // 24km
splits.push(converter::to_duration(0, 5, 42)); // 25km
splits.push(converter::to_duration(0, 5, 43)); // 26km
splits.push(converter::to_duration(0, 5, 42)); // 27km
splits.push(converter::to_duration(0, 5, 41)); // 28km
splits.push(converter::to_duration(0, 5, 36)); // 29km
splits.push(converter::to_duration(0, 5, 37)); // 30km
splits.push(converter::to_duration(0, 5, 34)); // 31km
splits.push(converter::to_duration(0, 5, 40)); // 32km
splits.push(converter::to_duration(0, 5, 47)); // 33km
splits.push(converter::to_duration(0, 5, 41)); // 34km
splits.push(converter::to_duration(0, 5, 51)); // 35km
let race: MetricRace = Race::new_from_splits(&splits);
let race_running: MetricRunning = Running::new_from_splits(&splits);
println!("The average pace of these {} splits is {}/km",
race.num_splits(),
formatter::format_duration(race.average_pace()));
}
It prints: “The average pace of these 35 splits is 5:39/km”. This is 16 seconds faster splits! What would be the finishing time if the pacer decided to maintain that pace until the end of the race? Adding to the previous code:
let faster_marathon: MetricRace =
Race::new_from_pace(MARATHON_DISTANCE,
race.average_pace());
println!("If he continued with the pace of {}/km to the finish line, \
he would finish the marathon in {} hours.",
formatter::format_duration(faster_marathon.average_pace()),
formatter::format_duration(faster_marathon.duration()));
}
It prints: “If he continued with the pace of 05:39/km to the finish line, he would finish the marathon in 03:59:06 hours”. This is almost 11 minutes faster! When runners are moving faster than what they trained for, they will hit the wall between 30 to 35 km, which is when their glycogen stores deplete. Therefore, any runner following that pacer would likely hit the wall and finish behind their initial goal.
Effectively balancing the energy consumption throughout the race, considering the elevation profile, and managing hydration and nutrition, definitely makes the marathon a strategic distance. We can have our strategy when we learn how our bodies perform under pressure or we can follow somebody else’s strategy, taking the risk of going off rails.
It is not about trusting a marathon pacer. It is about controlling as many variables as possible and being able to reason during the race whether it is a good idea to follow a pacer or not. For more tips on how to have more control over your pace, read this article published in Canada Running Magazine.
]]>LibRunner is an open-source library published on GitHub and distributed by creates.io. We decided to write it in Rust for the following reasons:
-
Performance: Rust is fast, compared to C, and often replaces C/C++ in production code due to its memory safety guarantees. The domain of sports often requires real-time features, so Rust allows calculations to be as fast as they can be, without the overhead of garbage collection.
-
Popular: Rust has been elected by an annual Stack Overflow survey as the most loved language for 7 consecutive years. It has a large and strong community of users and contributors as well as a great number of sponsors, from small start-ups to global players, investing in the language and its ecosystem. It implements the state-of-the-art on developer experience, making developers happy about the process of building high-performance software.
-
Reusable: Publishing LibRunner on creates.io is so straightforward that we did it as soon as its first feature was available. Today, any Rust project can add it as a dependency and use it for running-related applications. In the browser space, LibRunner can be used by WebAssembly applications. In addition to that, LibRunner can also be used by other programming languages through bridges. We intend to support other languages in the future in a on demand basis, ensuring the same underline logic across platforms and technologies.
-
High Level, yet native, writing Rust code feels like writing in a high-level language such as Kotlin, Scala, and C#. Yet, the result is native, platform-specific, and self-contained software.
LibRunner can help you calculate the average speed and pace to complete a distance within a duration, calculate the distance of a race from duration and pace, calculate the duration and distance of the race from a set of splits, calculate the pace of positive and negative splits of a race and so many other features that we are constantly adding to it as we learn more about the field. We are also open to suggestions, demands, and contributions.
In the LibRunner documentation, we have examples of code for every feature. These examples are guaranteed to work because the testing tool runs them against the current version. You can copy and paste them into your code and make the necessary changes to the problem you are solving.
Let’s go through these quick steps to get started with LibRunner. We start a Rust project from zero to unlock the way to hero:
-
visit https://rustup.rs and install rustup, an installer for the programming language Rust. Once installed, update and check the toolchain:
$ rustup update $ rustc --version $ cargo --version -
create your new running application:
$ cargo new runningapp -
a folder called
runningappis created. Go into it and run the project:$ cd runningapp $ cargo run -
it prints “Hello World”, meaning you have a working code to start from. Open the project in your favourite code editor and make two changes:
4.1. add LibRunner to the project’s dependencies:
$ cargo add librunnerIt adds a new dependency to your
Cargo.tomlfile:[dependencies] librunner = "0.6.0"4.2. replace the content of the file
src/main.rswith the code below:use std::time::Duration; use librunner::running::{Race, MetricRace, ImperialRace, Running, MetricRunning, ImperialRunning}; use librunner::utils::converter; use librunner::utils::formatter; fn main() { let duration = converter::to_duration(4, 0, 0); // 04:00:00 let m_marathon: MetricRace = Race::new(42195); let m_running: MetricRunning = Running::new(duration); println!("The pace to run {}km in {}h is approximately {}/km at {:.2}km/h", converter::to_km(m_marathon.distance), formatter::format_duration(m_running.duration()), formatter::format_duration(m_running.average_pace(&m_marathon)), converter::to_km_h(m_running.speed(&m_marathon))); let i_marathon: ImperialRace = Race::new(46112); let i_running: ImperialRunning = Running::new(duration); println!("The pace to run {} miles in {}h is approximately {}/mile at {:.2}mph", converter::to_mile(i_marathon.distance), formatter::format_duration(i_running.duration()), formatter::format_duration(i_running.average_pace(&i_marathon)), converter::to_mph(i_running.speed(&i_marathon))); } -
then run the project again:
$ cargo runwhich generates the following output:
The pace to run 42.195km in 04:00:00h is approximately 05:41/km at 10.55km/h The pace to run 26.2 miles in 04:00:00h is approximately 09:09/mile at 6.55mph
That’s it! You are now using LibRunner in no time. Keep an eye on this website to learn more about future updates and all things geeks love about running.
]]>
8 years ago I failed to write a book. I wrote it until chapter 3 but I couldn’t stand all the criticism coming from the editor and the reviewers. As the deadline to deliver chapter 4 was approaching, I was still overwhelmed by all the work to catch up with their feedback. So, I quit, but I learned something very important from that experience: the scrutiny over the writing of books makes them very good references.
It’s true that the time required to write and publish a book is incompatible with the rapid pace Information Technology evolves, making it quickly obsolete. However, Clojure is well known for its long term stability and backward compatibility. Clojure books have a very slow obsolescence and they are worth buying.
Most Clojure programmers I know, including myself, love to own Clojure books, but beginners may find interesting to have access to some books for free, before starting a new book collection. The Toronto Public Library is there to help.
I don’t know about other public libraries out there, but the Toronto Public Library is a model to follow. There is a central reference library where books are for your-eyes-only and dozen other branches all over the city, each one adapted to the needs of the neighbourhood. They offer not only books, but also e-books, audio-books, magazines, seminars, courses, all sort of multimedia material, image/video editing and 3D printing. When you subscribe, you gain access to all these services, most of them for free, with a library card that you can also use online to borrow books delivered to a branch near you.

This is a list of Clojure books you can borrow and keep for 21 days and renew them two times for the same length of time, making a total of 63 days!
- 2018
- Getting Clojure by Russ Olsen
- Programming Clojure by Alex Miller
- 2016
- Professional Clojure by Jeremy Anderson
- Clojure in Action by Amit Rathore
- 2015
- Living Clojure by Carin Meier
- 2014
- The Joy of Clojure by Michael Fogus
It is also possible to put your hands on books about other LISP languages:
- Practical COMMON LISP by Peter Seibel
- The Scheme Programming Language by R. Kent Dybvig

Even when some books aren’t physically available, they can be accessed online thanks to a partnership with Safari Books Online. I would highlight:
- Web Development with Clojure by Dmitri Sotnikov, a co-organizer of the ClojureTO Community.
- Clojure for the Brave and True by Daniel Higginbothan
Clojure is probably the most popular programming language among the functional ones. It is good to see that it is also accessible to everyone living in Toronto. When you borrow one of these books to learn it you’re going to fill a spark that will change the way you think about programming forever. It will be the beginning of your own Clojure book collection.
]]>
I was a Ph.D candidate in 2009, in the Electrical Engineering department, at Université catholique de Louvain. A coleague of mine, Russian, told me about this conference in Saint Petersburg and asked me if I wanted to submit a paper. I agreed, we wrote it together and it got accepted. Since she was in Moscow at the time, I thought she would present the paper, but our lab had a policy that they could only pay for trips from Belgium to Russia, not from Russia to Russia. So, I had to go.
The first step was to get a Visa. To my surprise, I needed an invitation from someone in Russia to be able to apply. Fortunately, the conference itself was the invitee. I went to the Russian consulate in Brussels, with all required documents, and my feeling was like getting into a secret service office to be interrogated. When it was my turn, the two-story security guy at the entrance pointed at me and commanded to hurry up inside. Short line, straight people, the process was actually fast. Perhaps because of my Brazilian passport, a friendly country that welcomes Russians for decades. In other words, a weak country afraid of any armed conflict. Some may say that if a world power invades Brazil, they would accept the new regime right away without fight, and wait for the carnival to reach peace.
It was a cheap flight, with connection in Frankfurt, Germany. I arrived in Saint Petersburg late afternoon, unaware of a big celebration that was taking place in the city: The Scarlet Sails during the White Nights Festival. The taxi driver had a hard time to drop me at the hotel because the streets were full of people and traffic jams, but nothing that distracted my attention from spectacular fireworks in the horizon. I finally arrived at the hotel and was eager to walk around, see the festivities, but for my astonishment, the receptionist confiscated my passport for inspection. They gave me a paper and asked me to pass by in the morning to recover it. I mean, really?! How can you possibly suspect that a Brazilian individual could be of any harm to Russia?! Let me tell you something about Brazilian espionage: the chef of our secret service released in his social networks a document showing he tested negative for COVID-19. Printed in his document was the equivalent of his social security number. The next day, hundreds of loans were taken on his behalf, he was registered as supporter of a soccer team, and even registered in a opposition party. As you can see, if I was a secret agent it would be clearly stamped on my face. Anyway, I was scared, but not in panic yet. Watching the fireworks through the window was somehow relaxing.

The next morning was a beautiful sunny day, the beginning of the conference. With my passport in hand, I walked all the way to the venue, enjoying a very charming city, full of people, parks, monuments, clean, and enlightened by the sun reflected on serene water channels. The conference was in the vicinities of the great Hermitage Museum, comparable to the Louvre in Paris. After finishing my presentation, I had the chance to visit the museum with fellow researchers and also went in a boat tour through the channels of the city. Everything was magnificent, showing all the progress Russia has achieved over the years, with the introduction of capitalism, after the fall of communism. Today, all that prosperity is in check, shrunken by the ego of a single insane person: Vladimir Putin.
In January 31, 1990, McDonald’s opened its first restaurant in the old Soviet Union. That day, the line of people stretched the length of five soccer fields. More than 30,000 ordinary Soviet citizens waited six hours or more. When they tried their first hamburger and fries, it really was a life-changing moment for them. Today, a huge number of companies are leaving Russia, including McDonald’s, some in protest to the aggression to Ukraine, others disrupted by broken supply chains. Russians learned to do many things from the occident, but its isolation will freeze its innovation. Thousands of highly skilled people already left the country and it will take a while for them to return - if ever - with this hostile government in power. The recovery of Russia to pre-conflict levels is certainly two generations apart.
That conference went well, I presented the paper, made good friends, but I’m afraid this war will put us apart for decades to come. I wish I could visit Saint Petersburg again, but I don’t think it will be possible any time soon due their isolation. Also, I never had the chance to visit Ukraine, but if I had I would be deeply sorry to know that all the places I visited are now destroyed by unprepared or ruthless soldiers. I hope Ukrainians get their territory back, join the European Union, get reconstructed and enjoy prosperity in the long term.

I’m over a year working in the healthcare industry. Before that, I was involved in education and finance. These are industries with significant impact on people’s lives, but the impact of healthcare is far more important because we may be poor or poorly educated, but being poorly healthy is a life threatening situation. A bug in an education system is upsetting, but it can be fixed without major impact. A bug in a financial system is troublesome to many people but they all have a chance to recover with the help of government and insurance companies. In a healthcare system, a bug can kill people. Loosing a simple allergy reaction record can represent severe complications during a surgery, for example.
There is no shortage of complex problems to solve in healthcare and they are pushing me to become a better engineer. While working at PointClickCare, I was exposed to a popular standard called HL7® FHIR®, which has been used not only to integrate heterogeneous systems, but also to enable a marketplace of applications that exponentially expands the offering of services for patients and care givers.
FHIR® (Fast Healthcare Interoperability Resources) is for healthcare what Swift is for finance. It is not simple. It takes some time to digest but it seems to have just enough complexity to cover the needs of healthcare without limiting systems and users. What I don’t get is the meaning of the word “Fast” in the acronym. I’m pretty sure it’s not about runtime performance. It depends on the library and the design of the system. I think it’s probably about productivity because there is a mature ecosystem out there to build solutions within hours, under the most optimistic circumstances of course.
FHIR® - pronounced like “fire” - structures healthcare data into resources, which also match the concept of resource in REST (RepResourceresentational State Transfer), making it an excellent standard to build healthcare APIs. Resources are composed of strongly typed elements. From that, we get that resources also follow the object-oriented paradigm in the way Java and C# implement it. They use abstractions similar to classes, attributes, methods, and inheritance. Resources are serialized in multiple formats such as JSON, XML, and RDF. The most powerful characteristic of the standard is extensibility. New resources can be created - by extending the Basic resource -, existing resources and elements can be extended, new elements can be added, all that while still compliant with the standard and without breaking interoperability. Here is how a Patient resource looks like in JSON format:
{
"resourceType": "Patient",
"id": "8973647",
"text": {
"status": "generated",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"><p><b>Generated Narrative with Details</b></p><p><b>id</b>: f001</p><p><b>identifier</b>: 738472983 (USUAL), ?? (USUAL)</p><p><b>active</b>: true</p><p><b>name</b>: Pieter van de Heuvel </p><p><b>telecom</b>: ph: 0648352638(MOBILE), p.heuvel@gmail.com(HOME)</p><p><b>gender</b>: male</p><p><b>birthDate</b>: 17/11/1944</p><p><b>deceased</b>: false</p><p><b>address</b>: Van Egmondkade 23 Amsterdam 1024 RJ NLD (HOME)</p><p><b>managingOrganization</b>: <a>Burgers University Medical Centre</a></p></div>"
},
"identifier": [
{
"use": "usual",
"system": "urn:oid:2.16.840.1.113883.2.4.6.3",
"value": "738472983"
}
],
"active": true,
"name": [
{
"use": "usual",
"family": "van de Heuvel",
"given": [
"Pieter"
],
"suffix": [
"MSc"
]
}
],
"telecom": [
{
"system": "phone",
"value": "0648352638",
"use": "mobile"
},
{
"system": "email",
"value": "p.heuvel@gmail.com",
"use": "home"
}
],
"gender": "male",
"birthDate": "1944-11-17",
"deceasedBoolean": false,
"address": [
{
"use": "home",
"line": [
"Van Egmondkade 23"
],
"city": "Amsterdam",
"postalCode": "1024 RJ",
"country": "NLD"
}
],
"maritalStatus": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v3-MaritalStatus",
"code": "M",
"display": "Married"
}
],
"text": "Getrouwd"
},
"managingOrganization": {
"reference": "Organization/f001",
"display": "Burgers University Medical Centre"
}
}But the Patient resource does not contain anything about the health of a patient. For that, we need other resources like Condition and Observation. The Condition below indicates that the Patient above has a mild form of asthma. Notice the reference to the Patient in the attribute “subject”:
{
"resourceType": "Condition",
"id": "example2",
"text": {
"status": "generated",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\">Mild Asthma</div>"
},
"clinicalStatus": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/condition-clinical",
"code": "active"
}
]
},
"verificationStatus": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/condition-ver-status",
"code": "confirmed"
}
]
},
"category": [
{
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/condition-category",
"code": "problem-list-item",
"display": "Problem List Item"
}
]
}
],
"severity": {
"coding": [
{
"system": "http://snomed.info/sct",
"code": "255604002",
"display": "Mild"
}
]
},
"code": {
"text": "Asthma"
},
"subject": {
"reference": "Patient/8973647"
}
}Many other resources are available to exchange healthcare data, but we don’t have to build anything from scratch to deal with those resources. There are many FHIR® implementations out there and one will probably match your stack, saving a ton amount of work. The most commonly used are Hapi FHIR (Java), Firely .NET (C#), and fhir.js (JavaScript). They are high level languages that match all abstractions required by the standard. Here are some advantages of using these libraries:
-
A single client implementation can connect and exchange data with multiple compliant servers.
-
We don’t have to build an in-house FHIR® client because one probably exists for our stack, giving us data ready to be processed.
-
If more data needs to be exchanged out of what FHIR® already offers, then the extension framework can be used to serve the data without breaking compatibility with existing clients.
Some active members of the community make FHIR® servers openly available for learning purpose. Hapi FHIR is one of those. Visit http://hapi.fhir.org/ to explore generated fake resources. We can even call the endpoints, as documented in the Swagger page:
$ curl --location --request GET 'http://hapi.fhir.org/baseR4/Patient/1963546'
This call returns the following response:
{
"resourceType": "Patient",
"id": "1963546",
"meta": {
"versionId": "1",
"lastUpdated": "2021-03-23T05:30:45.180+00:00",
"source": "#07OvOvGcTSCrnZYI"
},
"text": {
"status": "generated",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"><div class=\"hapiHeaderText\">Bob <b>ALEXANDER </b></div><table class=\"hapiPropertyTable\"><tbody><tr><td>Identifier</td><td>4f524274-0aca-4246-b20c-6d73e9862beb</td></tr></tbody></table></div>"
},
"identifier": [
{
"type": {
"coding": [
{
"system": "http://hl7.org/fhir/v2/0203",
"code": "MR"
}
]
},
"value": "4f524274-0aca-4246-b20c-6d73e9862beb"
}
],
"name": [
{
"family": "Alexander",
"given": [
"Bob"
]
}
]
}In addition to building APIs, FHIR® can be used to define messages to post in messaging systems such as RabbitMQ and Kafka. It can also be used to create documents that represent all records of a patient or an entire organization, with the intent of archiving or transferring large volumes of data. I can go on and on, listing everything that can be done with FHIR®, but this is a blog post, not a book. But, that’s probably a subject that I’m going to explore further, to help with its dissemination and perhaps to inspire other industries to take similar initiatives.
* HL7 and FHIR are the registered trademarks of Health Level Seven International and their use does not constitute endorsement by HL7.
]]>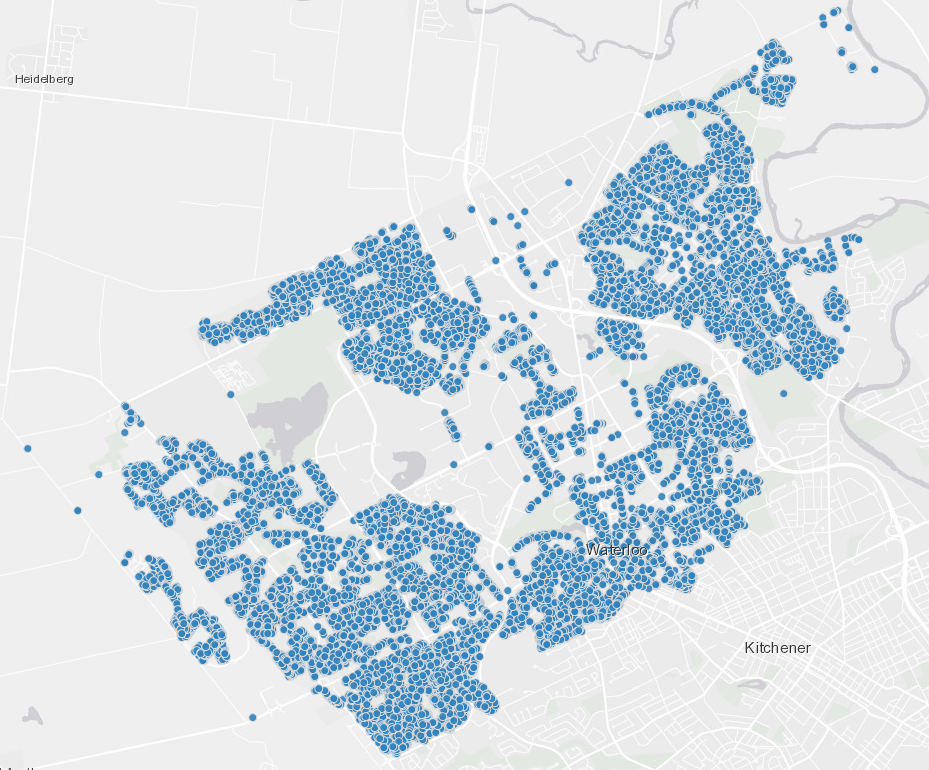
The City of Waterloo, located in Ontario - Canada, has an Open Data Portal that publishes raw data about infrastructure, services, environment, transportation, etc. Residents can use the data to oversee public investments and services, identify gaps, discover development opportunities, and even create new business. We figured out another use for the Portal: test CSVSource. It publishes a variety of CSV files. Among them, we found a an inventory of every single tree planted on the streets of Waterloo. Isn’t it cool?!
CSVSource’s goal is to convert a CSV file to a SQL file with insert statements, simplifying the data ingestion in relational databases. To have fun building CSVSource, we looked for an interesting dataset in the Open Data Portal and put it in the folder /examples. We are glad to inform that we’ve got the minimal Rust code in place to convert those CSV files to SQL. CSVSource implements convention over configuration, with the following default behaviors:
-
the name of the CSV file is used as the name of the table in the insert statements.
-
the first line is skipped because it contains the headers that describe the columns.
-
the headers in the first line are used as columns of the table.
-
the column separator is comma.
-
each line in the CSV turns into an insert statement.
-
if the value contains at least one alphanumeric character then it is quoted, but if the value contains a valid number then it is not quoted.
If you have these basic requirements then CSVSource is ready for you. Otherwise, wait for the availability of arguments that will customize these conventions. For the moment, simply type:
$ csvsource --csv waterloo_tree_inventory.csv
It converts this CSV:
X,Y,OBJECTID,TREEID,CIVIC_NO,STREET,LOCATION,SPECIES_NAME,SPECIES_LATIN,SPECIES_CODE,LANDUSE,ROADSEGMENTID,PARK,WARD,PLANTED_BY,MONTH_PLANTED,YEAR_PLANTED,STOCK_TYPE,STOCK_SIZE,STATUS,STATUS_DATE,CREATE_BY,CREATE_DATE,CREATE_YEAR,CREATE_MONTH,UPDATE_BY,UPDATE_DATE,SOURCE,SOURCE_DATE,OWNERSHIP,CATEGORY,ROOT_PATHWAYS,SOIL_VOLUME_M3,INITIAL_ACCEPTANCE_DATE,FINAL_ACCEPTANCE_DATE,OVERHEAD_HYDRO,DEVELOPMENT_AGE,PLANNING_COMMUNITY,SUB_WATERSHED,MAP_DBH_CM,GIS_NOTES,HEIGHT_ESTM_LIDAR_2014_M,HEIGHT_ESTM_LIDAR_2019_M,TAG1,GLOBALID,INSPECTED_YEAR
-80.5095189090518,43.412175164406,1,10007057,27,ACTIVA AVE,BOULEVARD,Autumn Brilliance Serviceberry,Amelanchier x grandiflora 'Autumn Brilliance',AMGRAB,ROW,40056,,5,CITY CONTRACTOR,NOVEMBER,2014,BALL AND BURLAP,50 mm,REMOVED,2020/07/30 12:53:44+00,,2015/12/23 10:34:03+00,2015,December,GIS_DATA,2018/03/05 17:14:35+00,Tree Inventory,,CITY,Small Tree,N,,,,None,1997,LAURENTIAN WEST,BORDEN CREEK,7,ADAM BUITENDYK,0,10,,0a2719cc-94b2-42c7-80b7-5dc0c5fe0f24,
-80.4806046253164,43.4464481686235,2,153401,10,CAMERON ST N,LAWN,Norway Maple,Acer platanoides,ACPL,ROW,11547,,10,UNKNOWN,UNKNOWN,0,UNKNOWN,UNKNOWN,ACTIVE,2017/01/31 15:14:06+00,Mark Grondin,2009/10/17 00:00:00+00,2009,October,Esri_Anonymous,2017/01/31 20:14:06+00,Tree Inventory,2009/10/17 00:00:00+00,CITY,Maple_Norway,N,,,,Three phase,1908,KING EAST,UPPER SCHNEIDER CREEK,55,Field Inspection,13,9,,f9ccd885-1a91-497c-b1df-4818419373ac,
to these SQL insert statements:
insert into small_waterloo_tree_inventory
(X, Y, OBJECTID, TREEID, CIVIC_NO, STREET, LOCATION, SPECIES_NAME, SPECIES_LATIN, SPECIES_CODE, LANDUSE, ROADSEGMENTID, PARK, WARD, PLANTED_BY, MONTH_PLANTED, YEAR_PLANTED, STOCK_TYPE, STOCK_SIZE, STATUS, STATUS_DATE, CREATE_BY, CREATE_DATE, CREATE_YEAR, CREATE_MONTH, UPDATE_BY, UPDATE_DATE, SOURCE, SOURCE_DATE, OWNERSHIP, CATEGORY, ROOT_PATHWAYS, SOIL_VOLUME_M3, INITIAL_ACCEPTANCE_DATE, FINAL_ACCEPTANCE_DATE, OVERHEAD_HYDRO, DEVELOPMENT_AGE, PLANNING_COMMUNITY, SUB_WATERSHED, MAP_DBH_CM, GIS_NOTES, HEIGHT_ESTM_LIDAR_2014_M, HEIGHT_ESTM_LIDAR_2019_M, TAG1, GLOBALID, INSPECTED_YEAR)
values
(-80.5095189090518, 43.412175164406, 1, 10007057, 27, 'ACTIVA AVE', 'BOULEVARD', 'Autumn Brilliance Serviceberry', 'Amelanchier x grandiflora ''Autumn Brilliance''', 'AMGRAB', 'ROW', 40056, NULL, 5, 'CITY CONTRACTOR', 'NOVEMBER', 2014, 'BALL AND BURLAP', '50 mm', 'REMOVED', '2020/07/30 12:53:44+00', NULL, '2015/12/23 10:34:03+00', 2015, 'December', 'GIS_DATA', '2018/03/05 17:14:35+00', 'Tree Inventory', NULL, 'CITY', 'Small Tree', 'N', NULL, NULL, NULL, 'None', 1997, 'LAURENTIAN WEST', 'BORDEN CREEK', 7, 'ADAM BUITENDYK', 0, 10, NULL, '0a2719cc-94b2-42c7-80b7-5dc0c5fe0f24', NULL);
insert into small_waterloo_tree_inventory
(X, Y, OBJECTID, TREEID, CIVIC_NO, STREET, LOCATION, SPECIES_NAME, SPECIES_LATIN, SPECIES_CODE, LANDUSE, ROADSEGMENTID, PARK, WARD, PLANTED_BY, MONTH_PLANTED, YEAR_PLANTED, STOCK_TYPE, STOCK_SIZE, STATUS, STATUS_DATE, CREATE_BY, CREATE_DATE, CREATE_YEAR, CREATE_MONTH, UPDATE_BY, UPDATE_DATE, SOURCE, SOURCE_DATE, OWNERSHIP, CATEGORY, ROOT_PATHWAYS, SOIL_VOLUME_M3, INITIAL_ACCEPTANCE_DATE, FINAL_ACCEPTANCE_DATE, OVERHEAD_HYDRO, DEVELOPMENT_AGE, PLANNING_COMMUNITY, SUB_WATERSHED, MAP_DBH_CM, GIS_NOTES, HEIGHT_ESTM_LIDAR_2014_M, HEIGHT_ESTM_LIDAR_2019_M, TAG1, GLOBALID, INSPECTED_YEAR)
values
(-80.4806046253164, 43.4464481686235, 2, 153401, 10, 'CAMERON ST N', 'LAWN', 'Norway Maple', 'Acer platanoides', 'ACPL', 'ROW', 11547, NULL, 10, 'UNKNOWN', 'UNKNOWN', 0, 'UNKNOWN', 'UNKNOWN', 'ACTIVE', '2017/01/31 15:14:06+00', 'Mark Grondin', '2009/10/17 00:00:00+00', 2009, 'October', 'Esri_Anonymous', '2017/01/31 20:14:06+00', 'Tree Inventory', '2009/10/17 00:00:00+00', 'CITY', 'Maple_Norway', 'N', NULL, NULL, NULL, 'Three phase', 1908, 'KING EAST', 'UPPER SCHNEIDER CREEK', 55, 'Field Inspection', 13, 9, NULL, 'f9ccd885-1a91-497c-b1df-4818419373ac', NULL);
To use CSVSource, please clone the repository locally and compile it from source. You will need to install Rust first, and then run the following commands:
$ git clone https://github.com/htmfilho/csvsource.git
$ cd csvsource
$ git fetch origin 0.1.0
$ git checkout tags/0.1.0 -b 0.1.0
$ cargo build --release
$ cargo install --path .
I’m still learning how to cross-compile CSVSource to multiple operating systems. Until then, we need to compile from source, but the usage is the same:
$ csvsource --csv waterloo_tree_inventory.csv
The output is the file waterloo_tree_inventory.sql in the same folder, with all insert statements.
In future releases, you will be able to:
-
change column separator to tab.
-
attach a prefix and a suffix content from other files.
-
set a table name different from the file name.
-
set the column names and their types different from the headers.
-
create insert statements that insert multiple records.
-
wrap multiple insert statements within a transaction scope.
But we are not limited to these. Let us know if you have any special needs by creating an issue in our repository.
Rust is definitely complicated. It took me a month to write the equivalent code that I wrote in 3 days in Go. The code might be memory safe, but I wouldn’t use the adjective “correct” like many Bloggers and Youtubers out there. A runtime panic exception is an evidence that correctness depends on the programmer, not the language. I still believe that Go is better than Rust, but it is delightful to see a Rust application running, using very minimal resources.
]]>
I almost never believe in predictions unless they match my owns. Only the future can prove them right or wrong, but I was astonished when I read this excerpt from the book The Demon-Haunted World by Carl Sagan. It literally summarizes what the World became in recent years.
“I have a foreboding of an America in my children’s or grandchildren’s time – when the United States is a service and information economy; when nearly all the manufacturing industries have slipped away to other countries; when awesome technological powers are in the hands of a very few, and no one representing the public interest can even grasp the issues; when the people have lost the ability to set their own agendas or knowledgeably question those in authority; when, clutching our crystals and nervously consulting our horoscopes, our critical faculties in decline, unable to distinguish between what feels good and what’s true, we slide, almost without noticing, back into superstition and darkness.
The dumping down of America is most evident in the slow decay of substantive content in the enormously influential media, the 30 second sound bites (now down to 10 seconds or less), lowest common denominator programming, credulous presentations on pseudoscience and superstition, but especially a kind of celebration of ignorance”
~ Carl Sagan
]]>
When we observed changes in the file system some posts ago – creating, modifying, and deleting files and directories – we hard-coded the location where we wanted to observe those changes. If we wanted to observe a different location we would need to change the code and recompile it. The world is simply not that static, so we better provide some flexibility to users. We can do it through flags, configuration files, and environment variables.
A configurable application adapts to different contexts, from specific user needs (home, work, etc.) to multiple deployment environments (development, staging, production, etc.). Anything that changes from a context to another or would push you to change the code to enable a new installation is a candidate to a configuration entry. Classical examples are database connections, credentials, file system paths, encryption keys, etc. The importance of configuration has been emphasized as the third factor in The Twelve-Factor methodology, which is used to design software-as-a-service.
Flags
Flags are the simplest yet the most verbose way of passing values to applications. They are passed only once, at the time of startup, as arguments in the command line.
$ ./mywebapp --port=8080
They are recommended when the values don’t change during the entire execution or when it isn’t convenient to have a configuration file, such as in ephemeral environments where resources are recreated at every deployment. In some cases, flags are the best option, like when indicating the location of a configuration file or changing the app behaviour fast. However, it is not recommended to use them for secret values because command lines leave traces in log files and automation tools like Jenkins.
In the following example we see how a flag is implemented in Go:
package main
import {
"fmt"
"flag"
}
var (
// flag name, default value in case the flag is not informed, and documentation
flgConfigPath = flag.String("cfg", "./config.toml", "Path to configuration file")
)The flag.String function looks for the flag --cfg in the command line. If it doesn’t find one then it returns ./config.toml, which is the default value. Using the file system observer example:
$ ./storage --cfg=../../config.toml
The example shows the use of a configuration file in a different directory. It is possible that some flags are redundant in configuration files and environment variables. When it happens, it is reasonable to assume that the flag takes precedence over the others. It allows temporarily bypassing a config entry for experimentation.
Configuration Files
Configuration files are the most maintainable way of keeping the configuration. They are text files, in a structured format, with documentation, and validation. They can be versioned, but in a different repository because using the same repository of the application would propagate changes to all environments, and expose secrets (e.g. database password).
Go developers like to use Viper to manage the app’s configuration. It supports YAML, JSON, TOML, HCL, and even Java properties files. It also covers flags and environment variables. In the following example, Viper takes the path from the flag --cfg to find the config file. It loads the file and makes its entries available to the application.
package main
import {
"fmt"
"flag"
"github.com/spf13/viper"
}
var configuration *viper.Viper
var (
// flag name, default value in case the flag is not used and documentation
flgConfigPath = flag.String("cfg", "./config.toml", "Path to configuration file")
)
func initConfiguration(conf *viper.Viper, filePath string) (*viper.Viper, error) {
conf = viper.New()
conf.SetConfigFile(filePath)
if err := conf.ReadInConfig(); err != nil {
if _, ok := err.(viper.ConfigFileNotFoundError); ok {
return nil, err
}
return nil, fmt.Errorf("config file was found but another error ocurred: %v", err)
}
return conf, nil
}
func main() {
configuration, err := initConfiguration(configuration, *flgConfigPath)
if err != nil {
fmt.Printf("Error initializing configuration: %v", err)
}
observedRootPath := configuration.GetString("observer.rootpath")
...
}The content of the config.toml looks like this:
[observer]
rootpath = "/home/username/liftbox"
So, instead of hard-coding the root path – as we did before – we make it configurable. Configuration files tend to grow overtime and it is important to keep them organized. Most of them support grouping, which is the ability of putting together entries that are strongly related. In the examples above, the [observer] directive is the grouping syntax of toml files.
It is not usual, but Viper also supports dynamic loading of changes in the configuration file while the app is running. It requires just a couple of extra lines:
func initConfiguration(conf *viper.Viper, filePath string) (*viper.Viper, error) {
...
conf.WatchConfig()
conf.OnConfigChange(func(e fsnotify.Event) {
fmt.Printf("Config file changed: %v\n", e.Name)
})
...
}As you can see, Viper also uses fsnotify to observe the config file.
Files are a good option to keep configurations. However, some environments are so volatile – like Kubernetes and Docker – that it is hard to properly manage them. That’s where environment variables come into play.
Environment Variables
Environment variables are a popular alternative to flags and configuration files. They are easy to set, language- and OS-agnostic, and keep the installation pretty clean. In the following example, Viper captures the value of the LIFTBOX_ROOTPATH environment variable:
func initConfiguration(conf *viper.Viper, filePath string) (*viper.Viper, error) {
...
_ = conf.BindEnv("observer.rootpath", "LIFTBOX_ROOTPATH")
...
}The variable is set this way on Linux and Mac:
$ export LIFTBOX_ROOTPATH=/home/username/liftbox/pictures
With the binding, the access to the value remains the same as in the configuration file:
func main() {
...
observedRootPath := configuration.GetString("observer.rootpath")
...
}Viper checks for the environment variable every time it is requested. So, it doesn’t require restarting the application to get newer values. You can check the changes I made in Liftbox to support configurations.
Configuration support is an essential feature of any application. It must be one of the first things to learn when starting to code and one of the first things to do in a new project. Many thanks to the community for the great configuration support we have for Go applications.
]]>
I have one of those things people call “car” that requires me to check its tires’ pressure once a month. I’m not really disciplined to check them every month, but at some point I feel guilty after noticing the car bending to the left. It is 1 year old and I might have checked it three times so far, but this time I decided to understand what I was doing. For my surprise, it was not straightforward in 2021.
I went to a gas station and was confronted with an air compressor that I’ve never seen before. It was like a box that accepts payment with coins and cards. Once you make an payment it starts working for a certain period of time, pushing pressured air through a hose that is long enough to reach all tire of the car. I checked the recommended pressure in the driver’s door and compared with the pressure chart sticked to the machine. Nice! Units matched, so I paid and got the air running, then took the hose down the tires. There is an adapter at the end that sticks to the tire’s valve and also measure the tire’s pressure. I’m not sure that thing is reliable though. Its unit was different from the one on the compressor, or maybe PSI divided by 10, not sure. The tire required 35 PSI, the adapter was showing 4.0, and the tire looked a bit low. Args! To put or not to put?

Suspecting there was a calibration problem with the adapter’s barometer, I decided to put 0.2 more, reaching 4.2. I suspect 4.2 is actually 42 PSI. At least the tires looked better, but I was afraid of over inflating it. So, I checked the manual and I found a way to see the pressure on the panel. It was in Bar, yet another unit.

I got 3 pressure units: PSI, Kpa, and Bar. Now I want to know their equivalence to understand how much I’m actually putting into my tires. There are thousands of unit converters online, but of course I have to write my own in Go. I have a feeling that it can be implemented using the strategy pattern, as we did before, but this time it would be without state. I have this book called Functional Programming Patterns that gives examples of how to achieve the same benefit of an object-oriented pattern in a functional language. Go is not a functional language, but it supports some functional features like higher-order functions.
Last time we used a struct to keep a state while running different algorithms around it. This time we pass an algorithm by parameter, in the form of a function, applying a different one for each call. In the example below, we create a new type Converter that represents a function that receives a float32 and return a float32:
package main
import "fmt"
type Converter func(float32) float32Then we use the new type in the convert() function to invoke any other function that matches the argument and the return types:
func convert (converter Converter, value float32) float32 {
return converter(value)
}The following functions make the pressure conversions and match the type Converter, making it possible to pass it as argument to convert().
func BarToPSI(bar float32) float32 {
return bar * 14.503773773
}
func PSIToBar(PSI float32) float32 {
return PSI * 0.0689475729
}
func KPaToPSI(kPa float32) float32 {
return kPa * 0.1450377377
}
func PSIToKPa(PSI float32) float32 {
return PSI * 6.8947572932
}
func KPaToBar(kPa float32) float32 {
PSI := KPaToPSI(kPa)
return PSIToBar(PSI)
}
func BarToKPa(bar float32) float32 {
PSI := BarToPSI(bar)
return PSIToKPa(PSI)
}We can finally call convert(), passing the conversion function we want and the value to convert:
func main() {
fmt.Printf("Bar to PSI: %v -> %v \n", 2.9, convert(BarToPSI, 2.9))
fmt.Printf("PSI to Bar: %v -> %v \n", 42.060944, convert(PSIToBar, 42.060944))
fmt.Printf("kPa to PSI: %v -> %v \n", 240, convert(KPaToPSI, 240))
fmt.Printf("PSI to kPa: %v -> %v \n", 35, convert(PSIToKPa, 35))
fmt.Printf("kPa to Bar: %v -> %v \n", 240, convert(KPaToBar, 240))
fmt.Printf("Bar to kPa: %v -> %v ", 2.9, convert(BarToKPa, 2.9))
}The code looks pretty expressive and extensible. The function convert() can be extended to perform some form of rounding or formatting and new compatible conversions can be added without changing existing logic. You can find the entire code at the blog examples repo. Running this code, we get:
$ go run convertall.go
Bar to PSI: 2.9 -> 42.060944
PSI to Bar: 42.060944 -> 2.9
kPa to PSI: 240 -> 34.80906
PSI to kPa: 35 -> 241.3165
kPa to Bar: 240 -> 2.4000003
Bar to kPa: 2.9 -> 290 %
It shows that the barometer was well calibrated because it is consistent with the other readings. I definitely over inflated my tires.
Owning a car brought a whole set of concerns to our lives. It is a big, complex, and expensive thing to take care of, but a necessity in North America, where public transport is limited. I know a thing or two about my car though I vastly rely on maintenance services to minimize my concerns. However, tire pressure is something that I have to do myself. I’m a user with an assigned task to be able to use the car. Why don’t they standardize it everywhere to a single unit? It doesn’t matter that 2.6, 35, and 240 means the same thing. What matters is to get the right pressure into the tire. Period.
]]>
Science has shown that shy people are clever because they spend more time listening and observing and less time speaking and showing off. They absorb more information and spend countless hours reasoning them. They do it quietly and are rarely recognized by their intellects. What science has not shown is that the Observer Design Pattern is also a humble part of a crafted designed software but rarely recognized as well.
You know you are in front of a observer implementation when an event happens and one or multiple routines react to that. The source of the event is normally called publisher and the code that reacts to that is called subscriber. You can actually have a propagation of events where subscribers also act as publishers, triggering other subscribers in a chain reaction. These two concepts are also popular in messaging systems, which is a way to implement the observer pattern in a distributed and decoupled fashion.
To illustrate the observer pattern in Go, we are going to watch for changes in a local folder. Every time a folder or a file is created, modified, or removed, an event is published and propagated to subscribers. To watch the local file system we rely on fsnotify. When something happens, we get events from fsnotify and propage the event to our subscribers. The full implementation is available in my Github repo. Let’s review it, starting with two interfaces:
type Publisher interface {
register(subscriber *Subscriber)
unregister(subscriber *Subscriber)
notify(path, event string)
observe()
}
type Subscriber interface {
receive(path, event string)
}The Publisher interface requires the implementer to register() and unregister() subscribers, and notify() subscribers about events. The observe() behaviour is specific for this case because the publisher is also a subscriber of fsnotify events. To be honest, the Publisher interface is not really necessary but, as we saw in the article about the adapter design pattern, it helps to encapsulate the fsnotify library.
The Subscriber interface is simpler, pushing the implementation of a receive() method that gets the message from the publisher. Let’s first look at the Publisher implementation: the PathWatcher struct.
// PathWatcher observes changes in the file system and works as a Publisher for
// the application by notifying subscribers, which will perform other operations.
type PathWatcher struct {
subscribers []*Subscriber
watcher fsnotify.Watcher
rootPath string
}
// register subscribers to the publisher
func (pw *PathWatcher) register(subscriber *Subscriber) {
pw.subscribers = append(pw.subscribers, subscriber)
}
// unregister subscribers from the publisher
func (pw *PathWatcher) unregister(subscriber *Subscriber) {
length := len(pw.subscribers)
for i, sub := range pw.subscribers {
if sub == subscriber {
pw.subscribers[i] = pw.subscribers[length-1]
pw.subscribers = pw.subscribers[:length-1]
break
}
}
}
// notify subscribers that a event has happened, passing the path and the type
// of event as message.
func (pw *PathWatcher) notify(path, event string) {
for _, sub := range pw.subscribers {
(*sub).receive(path, event)
}
}
// observe changes to the file system using the fsnotify library
func (pw *PathWatcher) observe() {
watcher, err := fsnotify.NewWatcher()
if err != nil {
fmt.Println("Error", err)
}
defer watcher.Close()
if err := filepath.Walk(pw.rootPath,
func(path string, info os.FileInfo, err error) error {
if info.Mode().IsDir() {
return watcher.Add(path)
}
return nil
}); err != nil {
fmt.Println("ERROR", err)
}
done := make(chan bool)
go func() {
for {
select {
case event := <-watcher.Events:
pw.notify(event.Name, event.Op.String())
case err := <-watcher.Errors:
fmt.Println("Error", err)
}
}
}()
<-done
}The observe() method get a watcher from the fsnotify library and, with the help of filepath.Walk(), watches the target path and all its sub-folders. Then, a goroutine starts an infinite loop, waiting for events from the file system. When they happen, the notify() method is called with information about the event.
We have two subscribers for this publisher: the PathIndexer, which would keep a database of references to the files, and the PathFileMD5, which would calculate the checksum of the files for consistence checks.
type PathIndexer struct {}
func (pi *PathIndexer) receive(path, event string) {
fmt.Printf("Indexing: %v, %v\n", path, event)
}
type PathFileMD5 struct {}
func (pfm *PathFileMD5) receive(path, event string) {
fmt.Printf("Syncing: %v, %v\n", path, event)
}These subscribers are not fully implemented because the goal is to show the observer pattern, but we will eventually implement them to push files to an Azure Storage Account. For the moment, let’s see how the publisher and the subscribers are put together in the main() function.
func main() {
var pathWatcher Publisher = &PathWatcher{
rootPath: "/home/username/liftbox",
}
var pathIndexer Subscriber = &PathIndexer{}
pathWatcher.register(&pathIndexer)
var pathFileMD5 Subscriber = &PathFileMD5{}
pathWatcher.register(&pathFileMD5)
pathWatcher.observe()
}The publisher is created with the attribute rootPath set with the absolute path to the folder we want to watch. Then we create the subscribers and add them to the publisher. Finally, we call pathWatcher.observer() to start observing the file system for changes.
As usual, you can find the full implementation in my Github repo. When you find some time, run the application with:
$ cd azure/storage
$ go run .
and in another console, run these commands:
In a console, run some basic operations:
$ cd /home/[username]/liftbox
$ mkdir pictures
$ echo "Blog Post" > post.txt
$ rm post.txt
Liftbox produces the following output:
Indexing: /home/htmfilho/liftbox/pictures, CREATE
Checksuming: /home/htmfilho/liftbox/pictures, CREATE
Indexing: /home/htmfilho/liftbox/post.txt, CREATE
Checksuming: /home/htmfilho/liftbox/post.txt, CREATE
Indexing: /home/htmfilho/liftbox/post.txt, WRITE
Checksuming: /home/htmfilho/liftbox/post.txt, WRITE
Indexing: /home/htmfilho/liftbox/post.txt, REMOVE
Checksuming: /home/htmfilho/liftbox/post.txt, REMOVE
This experience of revisiting the design patterns in Go has been an amazing experience so far. The challenge is to come up with ideas to describe them through realistic use cases. I take this challenge with pleasure because it is really cool to see useful cases materialized in Go.
]]>