Architects Need a Pragmatic Software Development Process
I have been a non-stop software architect since 2006. During my experience, I realized that it’s really hard to perform the role of architect in an organization that doesn’t have a software development process or have it too simplified. When the development is not fairly organized, project managers don’t find a room in their schedule to implement architectural recommendations. They probably have time, people and resources, but since they don’t have a precise idea of the team’s productivity, they feel afraid of accepting new non-functional requirements or changing existing ones. I’ve noticed that, in a chaotic environment, people become excessively pragmatic, averse to changes.
Architects expect that the organization adopts a more predictable and transparent software process. This way, it’s possible to visualize the impact of recommendations and negotiate when they are going to be implemented. They minimally expect a process that has iterations inspired on the classical PDCA (Plan, Do, Check and Act) cycle because it has loops with feedback, which are the foundation for continuous improvement.
The figure below depicts what could be considered as a pragmatic software process.
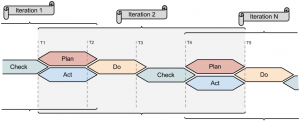
Iterations are overlapped in time in order to optimize people allocation, use of resources and guarantee the feedback from previous iterations. Each iteration is performed in a fixed period of time. This time depends on the context and it tends to fall as the organization gains more maturity. An iteration is composed of 4 phases (plan, do, check and act) and 5 events that may occur according to the planning. They are:
-
T1: It represents the beginning of the iteration, starting with its planning. The scope of the planning covers only the period of the current iteration. It should not be mixed with the general project planning, which is produced in one of the initial iterations to plan all other iterations. All members of the team participate in the planning.
-
T2: The execution of what was planned for the iteration starts. All members of the team must have something to do within the scope of the iteration. Nothing planned for future iterations should be done in the current iteration. People may produce all sort of output, such as documents, code, reports, meeting minutes, etc.
-
T3: Everything that is produced should be checked. Documents should be reviewed, code should be tested, user interfaces and integrations with other systems should be tested, etc. All found issues must be registered to be solved in due time.
-
T4: Solve all issues found during the check phase and release all planned deliverables. Everybody should deliver something. In case time is not enough to solve some found issues, they must be included in the planning of the next iteration with the highest priority. Statistics should be produced during this phase in order to compare the planning with the execution. The planning of the next iteration also starts at this point, taking advantage of the experience from the previous iteration.
-
T5: Once everything is released, the current iteration finishes. T2 of the next iteration immediately starts because most of people and resources are already available.
T1 to T5 repeats several times, in a fixed period of time, until the end of the project. This suggestion is process-agnostic, thus it can be implemented no matter what software process we claim to have in place or any other modern process we can think of.
In addition to the process, there are also some good practices:
- Consider everything that describes how the system implements business needs as use cases. It can also be functional and nonfunctional requirements, user stories, scenarios, etc; but there must be only one sort of artefact to describe business needs.
- Write use cases in a way that the text can be reused to: a) help business people to visualize how their needs will work; b) guide testers on the exploratory tests; and c) help the support team to prepare the user manual.
- Avoid technical terms in use cases. If really needed, technical details may be documented in another artefact, such as use case realizations.
- If needed, create use case realizations using UML models only. Representing use case realisations as documents implies on a huge overhead. Any necessary textual information can be added in the comments area of UML’s elements.
- Fix the size of use cases according to the effort to realize it. For example: we can fix that the maximum size of a use case is 1 week. If the estimation is higher than that, then the use case must be divided in two others. If the estimation is far lower than that, then the use case must be merged with another closely related use case. By simply counting the number of use cases we immediately know the effort and the resources required to execute the project. This fixed number is a parameter to compare the planning with the execution. By performing this comparison after every iteration, we gradually know how precise our estimations are becoming.
- Use a wiki to document use cases and other required documentations, such as test cases, release notes, etc. Create a wiki page for each use case and use signs to indicate what is still pending to be released. The advantages of the wiki are: a) use cases are immediately available for all stakeholders as they are gathered; b) stakeholders can follow the evolution of the use cases by following updates in the page; c) it’s possible to know everyone who contributed to the use case and what exactly they did; and d) it’s possible to add comments to use cases, preserving all the discussion around it.
- If the organization has business processes, which is another thing that architects also love, then put references in the business process’ activities pointing to the use cases that implement them. A reference is a link to the page where the use case is published on the wiki.
- Follow up use cases using an issue tracking system, such as Jira. Each use case must have a corresponding Jira ticket and every detail of the use case’s planning, execution, checking and delivery must be registered in that ticket. The advantages of linking Jira tickets with use cases are: a) Jira tickets represent the execution of the planning and their figures can be compared with the planning, generating statistics on which managers can rely on; b) we know exactly every person who contributed to the use case, what they did, and for how long; and c) it’s an important source of lessons learned.
- Test, test, test! It must be an obsessive compulsive behaviour. Nothing goes out without passing through the extensive test session.
- Constantly train and provide all needed bibliography to the team on the technologies in use. The more technical knowledge we have inside of the team, the highest is our capability to solve problems and increase productivity.
Working this way, everything becomes quantifiable, predictable, comparable and traceable.
From the practices above we can extract the traceability flow from business to the lowest IT level, as depicted in the figure below.
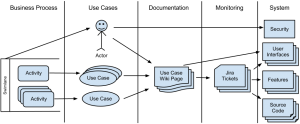
Business process elements such as swimlanes and activities may inspire actors and use cases. Use cases and actors are documented on wiki pages. Each use case and actor has a page on the wiki, which has a unique URL and can be used to refer the element on email messages, documents, Jira tickets and so on. An Jira ticket is created for each use case and it contains a link to the use case’s wiki page. This wiki page can also have a link to the ticket since it also has a unique URL. Jira tickets can be automatically linked the source code through the version control system (SVN) and declaratively linked to system’s features and user interfaces. Since it’s possible to create mock-ups in wiki pages, then we also link those wiki pages with user interfaces to compare the mock-ups with the final user interface. We finally have actors linked to security roles.
I admit that architects are not qualified to define and implement a software development process in the organization (they actually believe more in the Programming Motherfucker philosophy :D), but they are constantly willing to contribute to have one in place. As they have instruments to monitor servers, releases, tests, performance and so on, they also want project managers having instruments to estimate effort, predict events, anticipate problems and, therefore, produce better planning and results. Warning: Whatever we put in our software processes that is not quantifiable or measurable will become an expensive overhead.
Recent Posts
Can We Trust Marathon Pacers?
Introducing LibRunner
Clojure Books in the Toronto Public Library

Once Upon a Time in Russia

FHIR: A Standard For Healthcare Data Interoperability
First Release of CSVSource
Astonishing Carl Sagan's Predictions Published in 1995

Making a Configurable Go App

Dealing With Pressure Outside of the Workplace

Reacting to File Changes Using the Observer Design Pattern in Go

Provisioning Azure Functions Using Terraform
Taking Advantage of the Adapter Design Pattern

Applying The Adapter Design Pattern To Decouple Libraries From Go Apps

Using Goroutines to Search Prices in Parallel

Applying the Strategy Pattern to Get Prices from Different Sources in Go
