Using Python to Backup Files on Amazon S3

I was planning to upgrade my Linux System and one of my concerns was preserving my files. I don’t have a lot of files, but they are quite important. They occupe approximately 100GB. To solve this trivial problem I would simply perform a backup in an external drive with enough capacity and restore them later, hoping the driver won’t have any mounting issues. I could also upgrade my Dropbox account, which would give me a lot of space on the cloud, but for a bitter price.
In short, I decided to make my life harder by implementing my own backup application to copy my files to Amazon S3 and recover them later in case of losses. It definitively took longer, but at least I’m in control and paying less. For Dropbox, I would need to pay €10/month. With Amazon S3, I’m paying only €2.5/month.
I wanted this problem to be solved in a hard way, but not that hard. So I chose Python to focus on the problem not in technicalities. I found this quite powerful library, boto3, which allows Python scripts to make use of a vast variety of Amazon web services.
I have published the code I’ve written on GitHub. If you want to use it, continue reading.
What To Do On AWS Console
Login at AWS Console and go to the S3 service. There, you can create a bucket where the files will be stored.
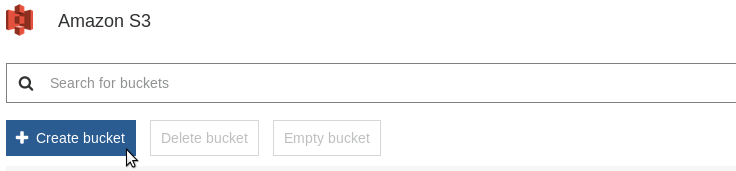
The user interface of AWS Console changes frequently. So, it’s better to follow the instructions published there.
To access the new bucket from a remote machine, you need to go to the IAM console and create your authentication credentials. For that, follow the instructions on the Boto3 documentation.
What To Do On Your Linux Machine
Make sure Git and Python3 are available in your system.
Let’s create a folder for the repository and clone it. If you follow my posts, you know I like this directory structure:
$ mkdir -p ~/python/projects
$ cd ~/python/projects
$ git clone https://github.com/htmfilho/personal-cloud.git
Enter in the repository folder and create a virtual environment (VE):
$ cd personal-cloud
$ python3 -v venv venv
This VE is used to isolate the dependencies of the project from the rest of your system. You will notice a new directory named venv, where the resources of the virtual environment are stored. It isn’t activated by default. We have to do it first to move forward with the dependencies:
$ source venv/bin/activate
Every time you want to use the app, don’t forget to activate the virtual environment, where the dependencies are available. Once activated, the prompt shows the name of the VE on the left. Let’s install the dependencies:
(venv)$ pip install -r requirements.txt
The app is ready, but we have some additional work to do to be able to connect to AWS. Create a directory in your user’s home folder named .aws to put AWS’ configuration files:
(venv)$ mkdir ~/.aws
There are two files to create: config and credentials. The config one contains details of the region where the S3 bucket is available:
[default]
region=us-east-1
and credentials contains the access keys to connect to AWS. The content of this file must look like this:
aws_access_key_id = WKTAG6BEC7P4ZH03MVKI
aws_secret_access_key = l2k2j3jg3hf4mnb9oaik3k190skmcne3i19486k2
Of course, these are invalid keys. You have to generate your own keys on the IAM Console.
These steps are useful to run the application, but they are also useful to contribute to the project. Therefore, do not hesitate to drop a few lines of code to improve it.
Using the App
Now, you are ready to run the app. In the example below, I’m copying all my local pictures to “mybucket”:
(venv)$ python backup.py -l /home/myusername/Pictures/ -r mybucket/media/pictures
The argument -l means “local” and -r means “remote”. For the moment, it only copies directories. Single files aren’t supported yet. For the -l argument, make sure it begins and finishes with /. For the “-r” argument, make sure it doesn’t begin and finish with /. Yes, I know, it’s silly, but that’s what happens when you don’t have enough time for this. Notice that the remote path starts with the name of the bucket.
To restore the backup, use the following command:
(venv)$ python restore.py -r mybucket/media/pictures -l /home/myusername/Pictures/
The rules of backup.py apply to restore.py. The difference is it performs downloads instead of uploads. The order of the arguments doesn’t matter in both cases. In summary, personal-cloud is easy to use, but it isn’t very flexible.
Future Directions
To be honest, Python is not the best language to do this. It works and it’s easy to implement, but the result is not suitable for users who doesn’t care about the implementation. Installing Git, Python, virtual environment, etc., is not for everybody.
I hope to find some time in the near future to rewrite it. Since the code is not very extensive, I think it would be possible to try it in C, Go and Rust to find out which one is the best for the task. I love Python, but some kinds of problems are better solved by other programming languages.
Recent Posts
Can We Trust Marathon Pacers?
Introducing LibRunner
Clojure Books in the Toronto Public Library

Once Upon a Time in Russia

FHIR: A Standard For Healthcare Data Interoperability
First Release of CSVSource
Astonishing Carl Sagan's Predictions Published in 1995

Making a Configurable Go App

Dealing With Pressure Outside of the Workplace

Reacting to File Changes Using the Observer Design Pattern in Go

Provisioning Azure Functions Using Terraform
Taking Advantage of the Adapter Design Pattern

Applying The Adapter Design Pattern To Decouple Libraries From Go Apps

Using Goroutines to Search Prices in Parallel

Applying the Strategy Pattern to Get Prices from Different Sources in Go
